2018.10.05

PISAから私たちは何を学べるのか? ――「学力調査の設計」という視点から
1.はじめに
前回の記事(1)でPISA調査の概要を説明しましたが、PISAから私たちが学べることは他にもいろいろとあります。今回は「学力調査の設計」という観点から、日本で実施されている全国学力・学習状況調査とPISAを比べ、学力を論じる前に知っておいてほしい「学力調査の基礎知識」について述べたいと思います。
はじめに、全国学力・学習状況調査とPISAの違いを整理しておきましょう。表1は、学力調査の目的や調査方法などについて、両者の違いを整理したものです。一見してわかるように、両者の設計には真逆の要素(悉皆調査に対して抽出調査など)がいくつもあります。

こうした差は、両者の調査目的の違いに由来するところが大きいと思われます。表1の一番上に記載しましたが、PISAが、その主たる目的を各国の「教育政策に活かす」ことに限定している(2)のに対して、全国学力・学習状況調査は、「児童生徒の指導に活かす」という目的を併せ持っています(3)。
学力調査を「児童生徒の指導に活かす」ためには、毎年度、すべての児童生徒のデータが必要です。そのため全国学力・学習状況調査では、調査サイクルが1年ごとに設定され、すべての児童生徒が同じテストを受験するという調査方式が採用されました(4)。さらに「指導に活かす」ために、全国学力・学習状況調査のすべてのテスト項目は、調査終了直後に公開されます。一方で、学校間の序列化を防ぎ、プライバシーを確保するという観点から、学力テストの個票データは非公開ですし、子どもの社会的属性(保護者の学歴や職業など)の情報も取得されていません。
表1からわかるように、全国学力・学習状況調査のこうした特徴は、PISAと大きく異なります。PISAは3年ごとに実施され、調査は抽出調査で行われます。受験者は全員が同じテストを受けているわけではありませんし、テスト項目も一部しか公開されません。その一方で、PISAの個票データはウェブサイト上に公開されており、誰でも自由に使うことができます。さらにPISAは、質問紙調査で受験者の社会的属性に関する情報を把握しています。
こうした違いを、たいしたことではないと思う人もいるかもしれません。全国学力・学習状況調査では、一人一人の子どもの得点がわかります。その得点を学校や市町村、あるいは都道府県で平均すれば、平均点の高い学校や地域、すなわち「よい教育をしている学校や地域」がわかるのだから、それで情報としては十分だろうというわけです。
残念ながら、この考え方は誤っています。学力調査の結果を教育政策に活かすには、PISAに倣った調査設計をしなければならないのです。以下では、全国学力・学習状況調査の何が問題なのか、PISAと比較しながら検討してみましょう。
2.全員が同じテストを受験することに伴う弊害
表1で見たように、PISAでは、すべての子どもが同じテストを受験しているわけではありません。なぜなら、すべての子どもが同じテストを受験すると、全体として見たときに、テストの精度が下がってしまうからです。
テストに使える時間の制約や、受験者の疲労といった問題があるため、1度のテストで1人の子どもが回答できるテスト項目の数には限界があります。そのため、全員が同じテストを受験するというテスト設計では、国語や算数(数学)といった幅広い調査領域のうち一部しかカバーできません。これでは、全員を調査したにもかかわらず、その国の子どもの得意・不得意な領域はわからないという事態が発生してしまいます。
幅広い領域をカバーするために、PISAで利用されてきた方法が、重複テスト分冊法(5)と呼ばれる技法です。これは、テストで出題したいテスト項目を複数のブロックに分割し、いくつかのブロックをまとめてテストの分冊を作成するというものです。さらに、分冊同士の内容が重なるように、ブロックを配置します(表2)。
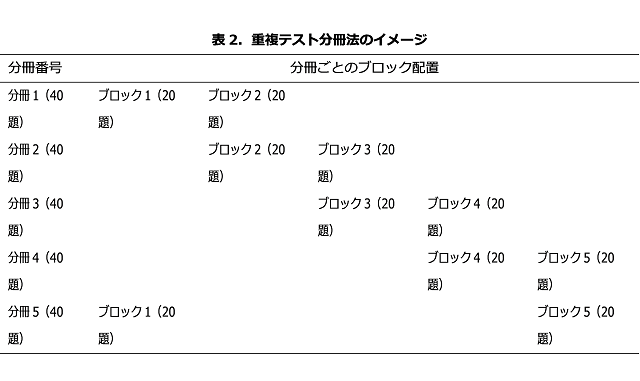
表2では、100題のテスト項目を20題ずつ5つのブロックに分割し、各分冊を2ブロックで構成しています。ここで、子どもたちには分冊1~5のうち、いずれかを受験させます。こうすると、1人の子どもは2ブロックのテスト項目(40題)に答えるだけで済む一方で、全体としては5ブロック分(100題)のテスト項目を出題することが可能になります。さらに、分冊同士に重複がありますから、この重複を手がかりに、一人一人の子どもの成績を比べることも可能です(6)。
もっとも、一人一人の子どもはテストで出題されたテスト項目の一部しか解いていませんから、その得点は正確なものではありません(7)。一方で、幅広いテスト項目を出題しているために、全体の状況はよくわかります。重複テスト分冊法とは「1人1人の得点を推定することよりも、全体の得点を推定することを優先した技法である」と言うこともできるでしょう。
PISAが、テスト項目をすべて公開していないことにも理由があります。先ほど重複テスト分冊法の説明のところで、共通のテスト項目を手がかりに成績を比べると書きましたが、この発想は、異なる年度のテストの点数を比べるためにも使えます。前回の記事で述べたように、PISAは各サイクルの得点を比較可能ですが、これは、各サイクル間で共通のテスト項目を利用することで可能になっているのです。
ただし、注意しなければならない点もあります。それは、肝心な共通のテスト項目は厳重に秘匿しないといけないという点です。共通のテスト項目を公開してしまうと、特別な対策をする人が出てくるかもしれません。そうなると、得点の変化の推定は失敗し、ある国の得点が上昇(あるいは下降)したのかどうか判断することができなくなってしまいます。つまり、教育政策のための学力テストを作るときは、テスト項目を公開してはならないのです。
他にも、全国学力・学習状況調査のように、調査サイクルが1年で、かつ、調査実施後にすべてのテスト項目が公開されるという仕様では、毎年、すべてのテスト項目をはじめからつくり直さなければならないという問題も生じます。PISAでは、数年をかけてテスト項目の予備調査が行われ、項目が適切に機能しているかどうか統計的な検討が実施されています。しかし1年サイクルの全国学力・学習状況調査では、予備調査を実施し、テスト項目の精度を検討する余裕はほとんどないでしょう。
以上のことからわかるのは、「児童生徒の指導に活かす」ために、全国学力・学習状況調査が備えている特性(すべての子どもが同じテストを受験する、1年サイクル、テスト項目はすべて公開する)が、学力テストを「教育政策に活かす」ために必要な特性(テストの精度や、異なる年度間での得点の比較)をダメにしてしまっているということです。「一人一人の点数を平均すれば全体のこともわかるだろう」という発想では、教育政策のための学力テストを設計することはできないのです。
3.社会的属性の情報がないと何が問題なのか
PISAでは、毎回、受験者の社会的属性を取得しています。それは、子どもの社会的属性が学力と関連していると考えられているからです。一般に日本では、社会的属性が学力に与える影響が軽視されているように思いますが、学力テストの点数を比較する際に、子どもの社会的属性を無視することには大きな問題があります。以下では、私たちが実施した文部科学省委託事業のデータ(8)を利用して、このことを示してみましょう。
図1は、西日本のある自治体の平成28年度の全国学力・学習状況調査のデータを利用し、学校ごとの国語の平均点(A問題とB問題を合算した正答率)と、校区に住む大卒者の割合の関連を示した散布図です。円の大きさは、各学校に所属する児童の人数を示し、大きい円ほど、大規模校であることを意味します(9)。
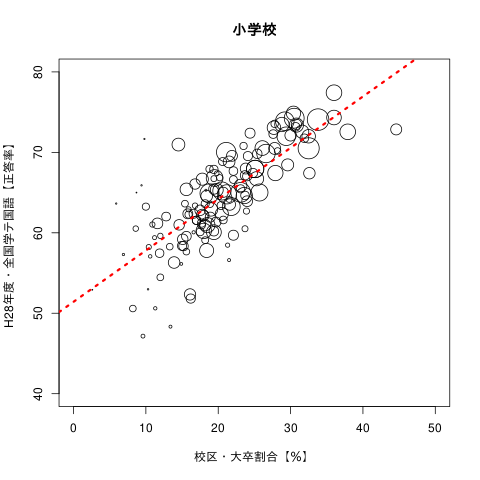
図1.校区の大卒割合×国語の正答率
一見してわかるように、校区に住む大卒者の割合が高い学校ほど、明らかに国語の正答率が高くなっています。全国学力・学習状況調査の正答率を見て、「学校(あるいは地域)の正答率が高いのは、学校や先生が頑張っているから高いのだ」と言う人もいます。しかし、この図を見れば、それが、あまりにも学校や先生の力を過信した、楽観的な見解だということは理解できると思います。子どもの社会的属性の情報のない学力調査から、学校の努力や教育政策の影響を知ることは、容易なことではないのです(10)。
なお、全国学力・学習状況調査ではほとんど触れられませんが、学力に関わる重要な社会的属性として、男女の学力差という問題があります。少し古いデータですが、全国学力・学習状況調査でも、国語の成績は女子の方が高い傾向があることが示されています(11)。少子化が進んだ近年、1学年が20人に満たない小規模校は珍しくありませんが、こうした学校では、女子の割合が高いという理由で、国語の平均点が向上することが起こります。こういった事例からも、学校の平均点の高低だけにこだわる無意味さは、よくわかると思います。
4.PISAから私たちは何を学べるのか
以上のことから私たちが学べるのは、「学力テストの設計には専門的な知識が欠かせない」という、ある意味で当たり前のことです。ここまで、重複テスト分冊法や、テスト項目を非公開にする理由、あるいは社会的属性の重要性などについて説明してきましたが、こうした知識を持っていないと、「一人一人の点数を平均すればいいだろう」と考え、現在の全国学力・学習状況調査で十分だと思ってしまう可能性は低くないと思います。
ここで1つ注意しておきたいことがあります。それは、日本の教育関係者の中には(おそらくは善意から)「児童生徒の指導に活かす」ために全国学力・学習状況調査を悉皆実施すべきだと考えている人も少なくないという点です。このことは、全国学力・学習状況調査に関する専門家会議の議事録(12)を読めばわかります。議事録には、「児童生徒の指導に活かす」ために悉皆調査が必要だという教育関係者の見解がいくつも掲載されています。「子どもの学びのために」「指導に活かすために」悉皆調査が必要だという主張は、一見もっともらしく聞こえるかもしれません。
しかし、かれらの主張は間違っています。なぜなら、全国学力・学習状況調査には「児童生徒の指導に活かす」という目的だけでなく、「教育政策に活かす」という目的もあるからです。「児童生徒の指導に活かす」ことを大事にしたいからといって、「教育政策に活かせない」学力調査を実施することを正当化できるわけではありません。
そもそも、全国学力・学習状況調査を「児童生徒の指導に活かす」必要はありません。普通の教員であれば、目の前の子どもの学習の実態について、日々の授業などを通して、テストからわかるよりも遙かに多くの情報を持っているはずです。どうしても学力テストが必要なのであれば、自分で目の前の子どもの状況に見合ったテストをつくるなり、あるいは市販のテストを使うなりすればいいだけで、わざわざ全国的な学力調査の結果を利用する必然性はないのです。
PISAの設計を見ればわかるように、「教育政策に活かす」ことと「児童生徒の指導に活かす」ことを1つの学力調査の中で両立することは容易ではありません。であれば、全国学力・学習状況調査において前者を重視し、「教育政策に活かす」ことのできる情報を収集することは、当然の選択であると私は思います。
“GIGO: Garbage In、 Garbage Out(集めたデータがゴミならば、それをどんなに立派に分析したところで、出てくる結論はゴミでしかありえない)”という言葉があります(13)が、これは、学力調査も同じことです。全国学力・学習状況調査が2007年に開始されてから、すでに10年以上が過ぎました。この間、毎年度、数十億円という規模の予算が、「教育政策に活かせない」学力調査につぎ込まれています。「学力テストの設計には、専門的な知識が欠かせない。」これこそ、まず私たちがPISAから学ぶべきことでしょう。
<注>
(1)https://synodos.jp/education/21701
(2)国立教育政策研究所編、2017、『生きるための知識と技能6』明石書店、p.39。
(3)文部科学省ホームページ「全国的な学力調査(全国学力・学習状況調査等)」http://www.mext.go.jp/a_menu/shotou/gakuryoku-chousa/zenkoku/1344101.htm
(4)この点は、全国学力・学習状況調査の10年目のまとめで、とくに強調されています。詳細については、「全国的な学力調査に関する専門家会議「全国的な学力調査の今後の改善方策について(まとめ)」を参照してください。http://www.mext.go.jp/a_menu/shotou/gakuryoku-chousa/__icsFiles/afieldfile/2017/03/30/1383338_1.pdf
(5)重複テスト分冊法については、たとえば『全国規模の学力調査における重複テスト分冊法適用の試み<http://www.mext.go.jp/b_menu/shingi/chousa/shotou/085/shiryo/attach/1312362.htm>が参考になります。
(6)ここで利用されているのが、項目反応理論というテスト理論のうち、「等化」と呼ばれる技法です。項目反応理論については、光永悠彦、2017、『テストは何を測るのか-項目反応理論の考え方-』ナカニシヤ出版などを参照してください。
(7)そのため、PISAで得点を推定する際は、誤差を補正するために推算値法(Plausible Values: PVs)という技法が利用されています。推算値法については、村木英治、2009、「社会調査としての学力テスト」『社会と調査』No.2、pp.35-42を参照してください。
(8)『児童生徒や学校の社会経済的背景を分析するための調査の在り方に関する調査研究』< http://www.mext.go.jp/a_menu/shotou/gakuryoku-chousa/1398191.htm>のうち、第6章のデータを、関連する自治体の教育委員会の許可を得て再分析しました。なお、校区の大卒割合は、国勢調査の小地域集計を使い、土屋隆裕先生(横浜市立大学)が算出したものです。
(9)図中の点線は、正答率を従属変数、大卒割合を独立変数としたときの回帰直線です。
(10)分析を工夫すれば不可能ではありません。一例として、妹尾渉・篠崎武久・北條雅一、2013、「単学級サンプルを利用した学級規模効果の推定」『国立教育政策研究所紀要』142、pp.161-173を挙げておきます。
(11)『子どもたちの学力水準を下支えしている学校の特徴に関する調査研究(成果報告書)』< http://www.mext.go.jp/a_menu/shotou/gakuryoku-chousa/1344297.htm>pp.6-10に、平成21年度の全国学力・学習状況調査から計算した男女の学力差が記載されています。
(12)全国学力・学習状況調査の分析・活用の推進に関する専門家検討会議 (第1回) 議事要旨<http://www.mext.go.jp/b_menu/shingi/chousa/shotou/045/gijigaiyou/08022911.htm>
(13)谷岡一郎、2000、『「社会調査」のウソ』文藝春秋、pp.23-24.

プロフィール

川口俊明
福岡教育大学教育学部准教授。大阪大学大学院人間科学研究科博士後期課程修了。専門は教育学・教育社会学。日本の学力格差の実態を明らかにするため、学力調査の分析や学校での参与観察調査をしています。
著書に『全国学力テストはなぜ失敗したのか』(岩波書店)、主な論文に、「教育学における混合研究法の可能性」『教育学研究』78(4)、 pp.386-397、「日本の学力研究の現状と課題」『日本労働研究雑誌』53(9)、 pp.6-15など。