2024.07.24

計量社会学
データサイエンス系学部の隆盛
本稿の目的は、計量社会学への招待なのですが、これから大学へ進学することを考えておられる方々を念頭において、最近目立ってきた大学学部の動向についてまずは触れさせてください。
2023年度、一橋大学が実におよそ70年ぶりに新学部を開設しました。「ソーシャル・データサイエンス学部」です。ここ最近、新設される大学の学部の多くが、データサイエンスに関連する学部です。以降、横浜市立大学、名古屋市立大学、京都女子大学などが続き、新たにデータサイエンス系学部を設置しました。2024年には、明治学院大学が、当大学初めての理系学部である「情報数理学部」が開設されました。データサイエンスを専門とする学部内のコース(学科)の設置を含めると、新規設置の数はかなりのものになります。
データサイエンス系の学部の設置のはしりは、2017年の滋賀大学による「データサイエンス学部」で、意外に思われるかもしれませんが、統計学やそれに関連する学問が核となる学部の設置は、これが日本で初めてのことでした。これまで日本では、計量分析の方法は各学部(理系学部の情報科学系コース、経済学における計量経済学、社会学部における調査統計、その他心理学や経営学など)においてバラバラに行われてきたのです。
この動きからは、二つのことが読み取れます。一つは、これまでの計量分析教育が、学部・研究科内での講義の設置でなんとかなってきた、あるいは「それでよい」と考えられてきたことです。計量分析は何らかの対象(労働でも教育でも家族でも)について研究するための「方法」なのであって、それだけを学ぶことは不自然だと考えられてきたこともあるでしょう。
実証分析としての評価から方法の評価へ
確かに、計量分析分野でのイノベーションが、しばしばノーベル経済学賞に値するほど重要視されてきたのは確かです。ただ、それは実証分析における何らかの具体的かつ固有の課題があり、それを解決するからこそ評価されてきたという側面があります。
たとえば2000年にノーベル経済学賞を受賞したジェームズ・ヘックマンは、「ヘックマンの二段階推定」を開発したことで有名です。この方法は、セレクション問題と呼ばれる実証研究における難問に対応したものです。たとえば「学歴がその後の賃金率にどの程度影響するか」(学歴の賃金上昇効果)を推定したい場合、やっかいなのは、しばしば高学歴女性が、やはり高学歴・高収入のパートナーと結婚した場合、非就業になりやすく、したがって賃金がそもそも観察されない(0である)傾向がある、という問題でした。そのまま分析してしまうと、高学歴女性の平均賃金率が低く推定されてしまいます。この点を計量手法によって補正する方法を提案したのがヘックマンでした。
ヘックマンはこの手法の開発で高い評価を受けたものの、専門はあくまで計量経済学で、たとえば就学前教育がその後の人生に与える影響など、大きなインパクトを持った研究を数多く発表しています。ヘックマンは、自分の関心のある具体的な研究課題を遂行する上で必要だから、計量手法を開発したのです。
いずれにしろ長い間、方法の評価は「実証研究における具体的な問題を解決するか」という点においてなされることが多かったのです。2013年にやはりノーベル経済学賞を受賞したラース・ハンセンは、一般化モーメント法(GMM)の開発で有名です。GMMはかなり汎用性が高い推定方法ですが、それでも評価ポイントは、ハンセンが行った資産価格の実証分析に置かれていました。
ただ、近年では若干違った流れが生まれつつあるように思います。これが、大学のデータサイエンス系学部設置の動きからみてとれる「二つ目」のポイントです。
2021年のノーベル経済学は、デヴィッド・カード、ヨシュア・アングリスト、グイド・インベンスの3名が受賞しました。受賞理由は、因果効果の分析(特に自然実験)における方法論の開発でした。3人の具体的な研究については、もちろんなされてはいますが、焦点にあたっていません。
近年の統計学では、「洗練された方法」をまず学び、それをさまざまな対象・課題に応用することも重視されるようになってきたのだと言えます。
データサイエンスでできる範囲
他方で、少し落ち着いてみると、また別の事態も見えてきます。データサイエンスが伝統的な統計学と違う点としてしばしば強調されるのは、「問題が先にあってそれにあわせて多様な分析を行う」ということです。たしかにデータサイエンスにはそういった側面があることは確かです。
他方で、データサイエンスには一つの制約があります。データサイエンスが本領を発揮するのは、ビッグデータが入手できる対象においてです。ビッグデータというと、数が極端に多いデータだと理解されがちですが、それだと100年以上前から行われている多くの政府の調査統計もビッグデータになってしまいます。データサイエンスが扱うのは、実際には「デジタルトレースデータ」です。デジタルトレースデータとは、企業の営利活動と人々の活動がデジタル的に、常時・自動的に記録されているデータです。小売店の販売データ、通信・SNSでの音声・テキストの記録などです。こういったデータは随時蓄積されていくもので、データの量も膨大になりますから、ビッグデータと呼ばれるようになったのです。
こういったさまざまなデジタル活動を通じて蓄積されたデータを、しばしば本来の目的とは異なった目的で分析して見せることがデータサイエンスの主要な役割のひとつです。たとえば無線通信サービスは通話・通信サービスの提供が目的ですが、GPSデータを利用して人の流れ・移動の分析に使うこともできます。販売データは在庫や搬入(ロジスティックス)の効率化に用いられますが、顧客データと組み合わせてマーティングや、場合によっては嗜好・価値観の分析にも使えることがあります。
ただ、デジタルデータがそうやって蓄積されていないと、そもそも分析自体ができません。しかもデータは、企業がデジタルデバイスを用いて営利活動をした副次的な結果であることがほとんどです。学生や研究者が「こういう分析・研究がしたいから、自分でデジタルデータを一から集めよう」と思っても、莫大なコストがかかるので、たいていは無理なのです。デジタルトレースデータは、企業の営利活動の結果として「ついでに」生成されるデータであるがゆえに低コストなのですが、企業にとってみれば研究者の研究目的など二の次の問題です。
そういう意味では、データサイエンスはかなり「受け身」な方法です。デジタルデバイスの普及により、教育、労働、家族形成など、さまざまな分野でデジタルデータは蓄積されていますが、それでもデータが自分の分析目的からして使えるかどうかは「運次第」でしょう。したがって、「入手しやすいデータから研究目的を考える」という受け身な方針にならざるを得ません。
企業の営利活動が研究目的の枠を決めるというのは、学問としては若干寂しいものがあります。研究目的が「価値観の実態調査」であるのなら、それに関連するデジタルデータがたまたまデジタル空間で生成されるのを待つのもありですが、研究者自身が積極的にデータをとりにいくことも必要です。
データサイエンスが「うまくいく」ケースというのは、データがすでに存在しており、何らかの方法でそれを利用することができ、さらにそのデータを特定の仕方で分析することが当初の目的に役に立つこと、といった条件がそろった場合になります。後にお話する社会調査データの分析と異なり、偶然の要素に左右されやすいという側面があるのです。
因果推論の限界
2021年のノーベル経済学賞であらためて脚光を浴びた統計的因果推論もまた、実証分析における見逃せない方法です。因果推論は、特に経済学と心理学、そして社会学でも、無視できない方法になっています。特に経済学と心理学の分野では、方法の主流を占めるといってもよいでしょう。
統計的因果推論の方法は、特定の介入(処置とも言われます)の効果を厳密に測定するためのものです。たとえば新型コロナワクチンに効果があるのかどうかを知るためには、ワクチンを接種するグループ(処置群と呼ばれる)と、接種しないグループ(統制群)の比較を行います。この際肝心なのは、処置群と統制群が――ワクチンを接種したかどうか以外の点で――全体として均質である必要がある、ということです。ここで、希望者がワクチン接種するというデザインで研究をしてしまうと、もしかするとワクチン接種者のなかに「慎重派(新型コロナにかかりたくない人たち)」が多く入り込むかもしれません。こういった人たちは、ワクチンを受けていても受けていなくても慎重に行動するかもしれず、発症率や重症化率が低くなるかもしれません。こうなると、ワクチン接種自体の効果はわからないままです。
もう一つ例をあげましょう。小学校などで、クラスの人数が少ないほうが学習効果は上がるのか、ということがしばしば教育の計量分析の分野ではテーマになってきました。クラスサイズの因果効果の研究です。ここで、クラスサイズが小さい学校の選択を人々に任せてしまうと、そもそも教育熱心な家庭の子どもが少人数学級の学校に集まってしまい、たとえ学習効果が上がっても、それがクラスサイズの効果だったのかがわからなくなります。
したがって実験では、処置群と統制群をくじ引きなどでランダムに分けるという手続きが行われます。これを無作為化比較実験といい、ほとんどの因果推論のモデルの原型になっています。
ここでかんじんなのは、特定の性質を持った人が処置群に流れ込まないようにすることです。実験では、誰がワクチンを受けるのか、誰が少人数クラスに配属されるのかは、研究者が決めます。しかし実験ができることばかりとは限りません。喫煙、就職、進学、結婚など、研究者の都合で決められないことはたくさんあります。それに、「処置の因果効果」というからには、処置が意味を持ち、一定である必要があります。ある人には5人の少人数クラス、別の人には15人の少人数クラスをあてがったりするなどの非統一性はできるだけ避けるべきです。ワクチン接種、クラスサイズ、児童手当などについては、処置の定義を一定にしやすいのですが、進学や結婚となると、その中身が多様になりすぎて、そもそもその因果効果が「何の効果」なのかを考えることが難しくなります。
因果効果の分析は、処置が定義しやすい、一定になりやすい性質の現象に向いています。しかし、社会の長期的な変化――進学率の向上、未婚化、雇用の不安定化――などを扱う際には、できることは限られてきます。「薬の効果を特定する」ための計量分析と、「社会の変化を知り、説明する」ための計量分析手法は、異なって当たり前です。そして計量社会学では、後者のテーマを扱うことが多くなります。
計量社会学の得意分野
社会学者が行っている実証分析は、計量的な分析以外にも、インタビュー調査結果の分析、資料(雑誌や新聞、行政の会議文書など)の分析など、実にさまざまな材料を取り扱います。
ここでは計量分析(すなわち計量社会学)に焦点をあてますが、計量社会学ではしばしば社会調査データを用います。典型的には、調査票(質問紙あるいはアンケート票という言い方も)を何らかの方法で配布し、それに対する回答を集計してデータを作成し、分析を行うのです。調査データとしては政府統計を扱うこともありますし、独自に調査を企画・実施することもあります。私自身、SSM(社会階層と社会移動)調査、JGSS(日本版総合社会調査)、NFRJ(家族に関する全国調査)という、社会学者が手動してきた三つの大規模社会調査にかかわってきました。研究者グループみずからが「どういうデータを取得するか」を考え、それに合致したデータの取得を目指す点が、デジタルトレースデータを用いるデータサイエンスとは異なった特徴です。
実際の調査に関わることが多いということもあって、日本の多くの社会学系の学部では、「社会調査士」という資格の取得課程を設定しています。大学院にいけば、さらに「専門社会調査士」の資格取得も可能です。かくいう筆者も専門社会調査士です。社会調査士は、行政や企業のみならず、多数存在する調査・リサーチ会社で働くなど、幅広く活躍しています。

計量社会学では、すでにみてきたデータサイエンスや因果推論の方法を用いることも増えてきました。東京大学の社会学者・瀧川裕貴先生は、日本の社会学分野で「計算社会科学」の研究を引っ張っています。扱う手法は、データサイエンスに近いものです。
因果推論の手法も、それが適したテーマについてはこれからどんどん研究が蓄積されるでしょう。たとえば「何が就職差別に影響するか」を知るために、対象者に就職採用係になって、採用の可否を判断してもらうという実験をしましょう。処置群と統制群に均質な情報を流すのですが、一点だけ(たとえば小さな子どもと同居しているかどうか)を変えて提示するのです。すると、どういう情報が特に就職の可否に影響しやすいのかが的確に判断できるのです。
社会学はこれまでも、対象や社会の実態に合わせて柔軟に方法を変えてきました。記録があまり残っていない前近代の社会の場合、絵画を用いることもあります。20世紀のはじめころのシカゴ大学の社会学グループでは、当時増えつつあった文書記録(日記や手紙など)を用いた生活実態の研究がさかんでした。
現在では、非常に多くの人がウェブを介して活動をしています。それにあわせて調査票調査も、郵送などの古典的な方法のみならず、登録されたウェブモニターを対象とした、安価でスピーディな方法が利用されるようになってきています。
多くの社会学者は、人々の生活、人生、考え方などの実態に関心を持っています。その目的に応じて、データの入手方法や分析方法を変えることになります。ただ、大きな傾向としては、データサイエンスや因果推論にとらわれない研究が多いと言えるでしょう。
すでに述べたようにデータサイエンスを用いたデジタルトレースデータの分析は、データの入手において受け身になりやすく、必ずしも人々の生活実態をバランスよく捉えることには向いていません。
因果推論も、薬の処置や政策の効果といったテーマについては本領を発揮しますが、やはり人々の生活をバランスよく理解するという目的については、あまり役に立たないことが多いのです。たとえば筆者は「なぜ日本人は結婚しなくなってきたのか」というテーマをたて、実に60年間におよぶ行動の記録データを用いて結婚行動の変化を計量分析したことがありますが、因果推論やデータサイエンスの手法は全く必要ではありませんでした。
計量社会学では、対象に寄り添い、リアルな感覚でそれを深く、多面的に理解することが求められます。結局のところ、私達の個々の行動や選択は、具体的な場面に埋め込まれた複雑なものです。私と前田泰樹先生(立教大学)が2人で執筆した『社会学入門』(有斐閣ストゥディア)には、人々が「出産」をめぐる複雑な判断を経験していることが描き出されています。出生数としてカウントされれば「1」ですが、その内実は極めて多様で、とても同じ「1」であるとは思えないようなものです。
もちろん「数字に何がわかるのか」といった悲観的な見方をしたいわけではありません。かんじんなのは、数字を扱う際に、数字のクセを見抜く力を習得することです。熟達した計量分析研究者は、これを身につけています。
ここでクイズに挑戦してみましょう。以下に、二つの調査票調査の設問がありますので、まずは見てください。実は、この二つの設問は、「役に立たない」ものです。それはなぜでしょうか? 考えてみてください。
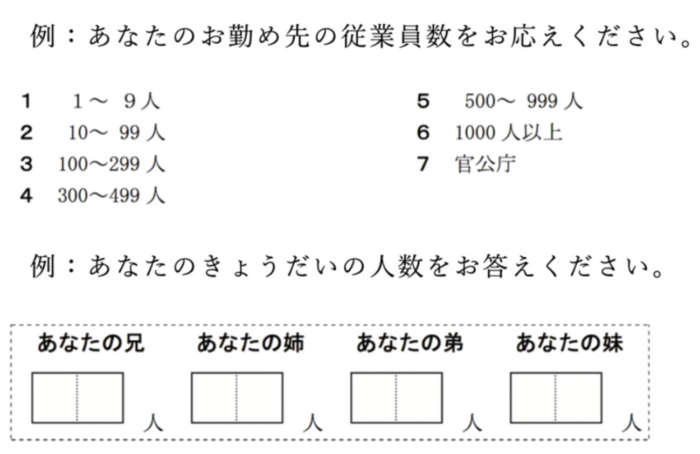
まず上の例ですが、この設問だと「従業員数」が会社全体のものなのか、それとも回答者が所属している事業所(支店など)のものなのかがわかりません。ある回答者は「全体」で回答し、別の回答者は「事業所」で回答する可能性があります。となれば、十分にデータがそろっておらず、せっかく調査をしたのに全く使えない情報になります。
次に下の例ですが、これだと一部の回答者は「存命(健在)」の兄弟姉妹数を、一部の回答者は「死去した人を含めて」の数を書き込む可能性があります。やはり、まざってしまっては使えないデータになってしまいます。
拙著『数字のセンスを磨く』(光文社新書)に詳しく書きましたが、数字を扱うことには、人々のリアルな思いや生活実態についての深い知識と想像力が必要です。計量社会学者は、調査研究の蓄積を通じて、こういったスキルをたくさん蓄積させてきました。その能力は、広く社会で必要とされるものです。
計量の世界を泳ぎ回る
計量の世界と言ってもさまざまだ、ということがちょっとだけおわかりになられたでしょうか。
さまざまな分野があるとはいえ、「どれかの道を選んだらそれまで」ということはありません。データサイエンスの手法を学びながら、社会学で調査研究を行うことも十分にありえます。大学のカリキュラムは、みなさんが考えている以上に柔軟です。他学部の授業を取ることもある程度可能ですし、それこそ「学部ではデータサイエンス、大学院からは社会学」のような道筋をとれば、他の人と比べて視野も方法も広く、キャリア上の優位性につながることもありえます。
どの大学にも、一定規模以上の社会学系の学部があれば、計量社会学を学ぶことができますし、社会調査士の資格を取得することもできます。就職先についてもさまざまな可能性があります。近年は行政(政府や自治体)でも企業でもウェブ調査のデータを活用することが増えたこともあり、調査会社の数が増えています。もちろん政府・自治体や企業内部に所属して、調査部門の担当になることもありえます。
ただ、どんな場所でどんな仕事をする際にも、データの背後には人々の生活のリアリティがある、ということを忘れないようにしてください。そうすることではじめて意味のある数字の分析ができるのです。

プロフィール

筒井淳也
立命館大学産業社会学部教授。専門は家族社会学、計量社会学、女性労働研究。1970年福岡県生まれ。一橋大学社会学部、同大学院社会学研究科博士課程後期課程満期退学、博士(社会学)。著書に『仕事と家族』(中公新書、2015年)、『結婚と家族のこれから』(光文社新書、2016年)、『社会学入門』(共著、有斐閣、2017年)、Work and Family in Japanese Society(Springer、2019年)、『社会を知るためには』(ちくまプリマー新書、2020年)、『数字のセンスをみがく』(光文社新書、2023年)など。