2015.04.09

失った声を取り戻す――「ボイスバンクプロジェクト」の挑戦
最先端の音声合成技術をつかい、病気で声が出無くなってしまった方の声を取り戻す「ボイスバンクプロジェクト」。「ボイスバンクプロジェクト」とはなにか、最先端の音声合成技術がどのように医療分野に使われているのか、自分の声を取り戻す意義とは。プロジェクトの代表者である、山岸順一氏にお話を伺った。(聞き手・構成/山本菜々子)※本記事は電子マガジン「α-Synodos」vol.155(2014年9月1日号)より転載しております。
「平均声」で出来ること
――最先端の音声合成技術を使って、病気で声が出なくなってしまった方の声を取り戻す「ボイスバンク」プロジェクトを行っている、山岸順一先生にお話を伺いたいと思います。山岸先生のご専門はなんでしょうか。
私は医療ではなく、数学を使った音声情報処理や、音声合成を専門としています。なぜか、縁あって医療の分野と関わっています。
「音声合成」と言われると、あんまりピンとこないかもしれませんが、カーナビのような音声読み上げ機能や、最近ではボーカロイドなど、様々な場面で技術が使われています。
――身近な技術ですね。山岸先生はどのような研究をされていたのでしょうか。
これまでの音声合成は、大規模な音声データが必要でした。本人の声を再現するためには、一人数百時間や、何か月にもわたってスタジオで収録するのが主流です。
それをなんとか数学で面白く、実用的にできないかと考えました。そこで、その人自身の声だけではなく、他の人達の声を集めて、平均声をつくり、その平均声を基にして、目標の声をつくるという方法を思いつきました。
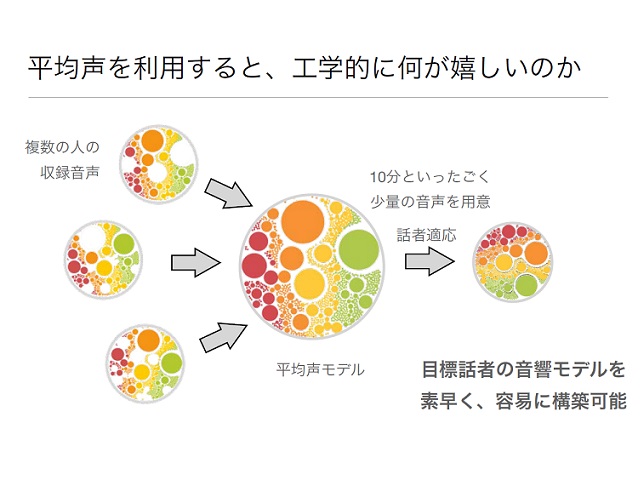
―――たくさんの人の声を集めて、声の雛型をつくってから、目標の声に近づけるわけですね。そのメリットはどこにあるのでしょうか。
平均声を利用することで、その人の収録時間がかなり減らせます。今まで本人の声を再現するのに、本人の声で数十時間~百時間の収録が必要でしたが、今では10分ほどの収録で、その人らしい声をつくことが可能です。この技術を開発したのが2002~2006年ごろですね。
当時は、医療分野に応用しようとは明確に考えておらず、単純な数学的興味から取り組んでいました。
自分の声はアイデンティティ
――なぜ、医療分野に音声合成の技術を使ってみようと思ったのでしょうか。そのきっかけはなんですか。
実は、当時指導を担当していたシーフィールド大学の学生さんがきっかけなんです。音声合成の技術がALSなどの方が使う意思伝達装置の音声合成器に利用できるのではと、提案してくれたんです。
そこで、喉頭を摘出する前の音声を7分収録して、当時私が持っていた平均声のツールを提供して音声合成器を作りました。これが2007年のことです。
技術的には2006年にほぼ完成されていましたが、医療を対象にすることが新しかったので、イギリスの新聞でも記事になり、とても反響がありました。
――医療分野と組み合わせることが画期的だったんですね。「意思伝達装置」とはなんですか。
意思伝達装置――重度障碍者用伝達装置ともいわれますが――科学者のスティーヴン・ホーキング先生が使っていることで有名です。声に障害が起こってしまったときに、合成音声で会話の補助をするものです。
これまでの、市販されていた意思伝達装置は、合成音声で読み上げてはくれますが、声の種類を選べませんでした。せいぜい、男性か女性かを選択できる程度です。その人の年齢や方言、発話様式、たとえば、関西出身か東京出身か、それらを適切に表現できているとは言い難いものです。
――たしかに、機械的な音声で読み上げているイメージがあります。
本人の声を使った音声合成器もありますが、非常に高額です。つくると100万円はかかってしまいます。そもそも、意思伝達装置自体も100万円ほどします。しかも、収録にかなりの時間が必要です。ただでさえ声を出すのがつらい状態なのに、何百時間も収録するのは患者さんにとってはかなり大きな負担です。
日本ではウォンツさんなどが、本人の声をつかった音声合成器を提供しています。
巨大なデータベースから、声を切り貼りする手法をとっていますし、収録した膨大な音声データを整備する費用もあって、一人の声をつくるのに非常にコストがかかります。
――自分の声は高級品なのですね。
そうはいっても、つい数か月前まで喋れていたのに、急に喋れなくなるというのは心理的な負担が大きいですよね。
英国で研究していた時、あるALSの男性から自分の声で音声合成器を作れないか打診されたことがありました。でも、彼はもうすでに2つも音声合成器を作っていました。
なぜ、そんなに自分の声の音声合成器を作りたいのか、疑問に思い聞いてみたんです。彼は、自分のお子さんに自分の声を覚えて欲しいと語っていました。自分の声はアイデンティティだとも。
親しい人たちに、自分の声を覚えて欲しいし、周囲の人も患者さんの声を聴きたいでしょう。自分の声を残すことに、強い思いを持つのは不思議ではありません。
そんな人にぜひ音声合成器を届けたいと思いました。私の開発した平均声の技術が役にたつと思ったんです。実は、2006年までALSのことを知りませんでしたので、色々と声の障害について勉強することになります。
そして、ALSなどを専門に研究しているユアン・マクドナルド研究所が、2011年にALSの患者さんの声を診断直後に収録していましたので、その音声を基に音声合成器をつくりました。症状が進んだ9か月後に、会話補助アプリとして届けました。
その際、当時持っていた平均声をそのまま使ったのですが、方言の強い英国の北の方に住んでいたので、普通の平均声では忠実に再現できませんでした。
ですので、その地域の方20名に協力していただき、地域の方言の平均声をつくりました。そこから患者さんに近い声をつくることができました。
――地域の平均声をつくることで、方言にも対応することができるんですね。
やはり、方言も自分の声をつくる大きな要素ですし、大切なアイデンティティだと考えています。
――私は地方出身者なんですが、もし例文を読めと言われたら、勝手に標準語で読んでしまうと思います。そのあたり難しいかなと感じたのですが。
文章を用意するむずかしさはありますね。イギリスの方も、アメリカ英語で例文を渡されると、自分の方言でしゃべれなくなってしまいます。ですので、方言を再現しやすい例文にするよう気をつけています。
日本でやる場合、関西の方言などは違いが分かりやすくていいですが、名古屋などの方言は難しいですね。文章を用意するのもけっこう大変です。また、琉球方言など、消えかかっているものをどう組み込んでいくのか、そのあたりも色々と考えなければいけません。
なぜALSか
――そこから、ALSの方を中心にした音声合成器の開発に力を入れていますよね。数ある病気の中で、ALSを中心にしたのはなぜでしょうか。
日本やアメリカでは単に「ALS」と呼ばれますが、正確にはMNDの症状の一つがALSです。ですので、厳密にいえばMNDですね。イギリスではMNDという呼び名が一般的です。でも、ここでは、「ALS」と統一してお話したいと思います。
ALS患者は頭の中の運動ニューロンが消えていき、筋肉を動かせという伝達命令が届かなくなって、結果として筋肉が弱くなって声も出なくなってしまいます。患者さんの75%に声の障害がおこると言われています。
とはいえ、ALS以外にも、声の障害を伴う病気は数々あります。ALSやパーキンソン病が進行性の声の障害とするならば、小児麻痺は先天性の障害と言えるでしょう。舌のガンや脳卒中は突発的な障害と位置づけられます。
ボイスバンクはどのタイプの病気も対象にしていますが、ALSを中心として取り組みをはじめました。ALSは進行性ですので、初期や中期の段階で収録が可能です。病気が発覚してすぐ録音すれば、音声合成器が必要になる後期に提供できます。技術の面とニーズとが適合していると言えますね。

元の声に修復せよ!
――平均声の技術を利用して、より安く、より簡単に、しかも方言なども再現した患者さんに近い声を提供できるようになったことが分かりました。
そこで、提供するALSの患者さんを広げる取り組みをはじめたのですが、もうひとつの課題が浮かんできました。
はじめの事例では構音障害がない状態の音声から、音声合成器をつくりました。しかし、たいていの場合は、構音障害がない時点で録音できません。
体のどこかがおかしい、声がおかしい、という異変を感じて、診断を受けられるケースが多いわけです。ですので、多くの方は診断直後の時点で、構音障害が起きてしまっています。
まずは、既存の技術をそのまま使うとどうなるか試してみました。すると、録音した音声を再現するので、音声合成器もそのまま障害を再現してしまうんですね。
でも、患者さんが利用したいのは、構音障害のある声ではなく、元の自分の声ですよね。障害を伴った音声からどうやって、元の声をコンピューターが推測して音声合成器を作れるのか、模索を始めました。
――元の声に修復する、という課題が生まれたのですね。その課題をどう乗り越えたのでしょうか。
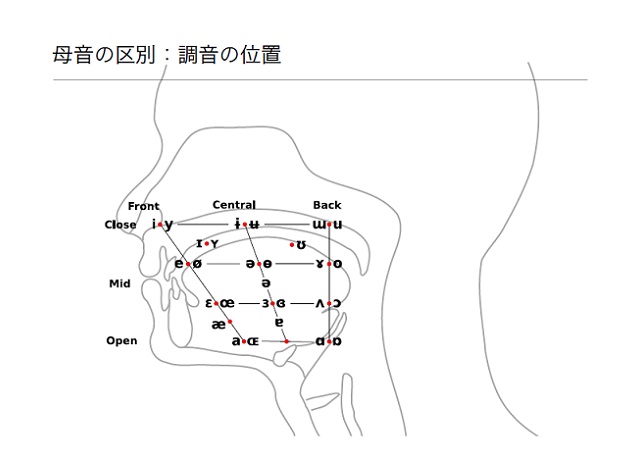
母音を発音する際の位置関係に注目しました。母音は、口の中のどこで舌を動かすのかによって区別されます。Iはここ、Eは口の真ん中、Oは口の奥、などとだいたい決まっているんです。
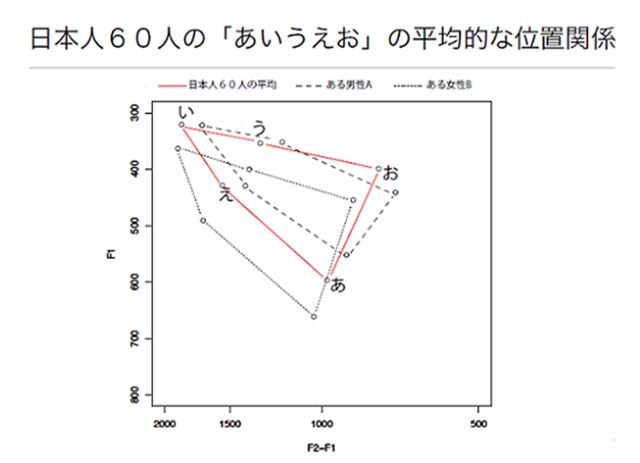
日本人は、口の中のどのあたりで母音を発声しているのか。日本人60人の平均でみるとこのようになります。イギリスではまた異なった位置で母音を発声しています。
――国によって違うんですね。
そうですね。日本人の「あ」とイギリスの「a」では違います。個人性はありますし、国によっても違いがあります。
それらの位置関係を結ぶと、三角形があらわれます。口の大きさは人それぞれですから、頂点は違っていますが、三角形の相対的な関係は似ているんですね。
そして、「あいうえお」の相対的な位置関係は、同じ方言の中では共通です。これを「母音三角形」と言います。この母音三角形の情報をうまく使って復元することを考えました。
実際にはもっと複雑なことをやるのですが、コアのアイディアを説明したいと思います。
たとえば、患者さんが構音障害により、「あ」と「う」しか発音できなくなってしまったとします。ほかの「い」「え」「お」はしゃべれないと。もとの声を再現するためには、この「あ」と「う」から母音の「い」「え」「お」を類推することが必要です。
そこで、先ほどの母音三角形の平均を使うんです。「あ」と「う」を三角形に合わせると、同時に「い」「え」「お」もこの辺にあるのではと、類推できるんです。
実際はもっと細かくて難しいです。たとえば、英語には二重母音がありますね。短い音の中で音が変わるような母音です。この2重母音を発声するときには口の中で、eからiに急速に舌を動かすなどの作業が必要です。
舌を動かす筋力が弱っているALSの方には、非常に困難な発声だったりします。急速に舌を動かすのが難しいんですね。
こういった場合にも、コンピューターがもとの声を類推します。iとeを発声出来るのなら、あとは舌を動かすスピードが必要です。ほかの人の舌の動かすスピードを参考にして声を再現します。
――すごい技術ですね。
大事なのは、他の人の母音三角形を使っている点です。ほかの人の声のヒントがあったから、コンピューターはそれを手がかりに、発生できない「い」「え」「お」をその人が発生できる「あ」「う」から類推できた。
他の人の母音三角形や2重母音での舌を動かす速度、加速度を計算することで、発音できない声を補うことができます。
――母音三角形のサンプルは、一人でいいのでしょうか。それとも、平均声をつくる時のように20人ほど集めた方がいいのでしょうか。
技術的にはどちらでも可能です。もし、ご自身に双子や、同性の兄弟・姉妹がいらっしゃるのではその人を参考にするのがいいと思います。年齢、性別、社会方言が一致しているので、限りなく本人の声を修復するうえで参考になります。
しかし、そのような兄弟がいないケースももちろんあります。そういった場合は、特定の人よりも、方言・年齢・性別が同じな人達を集め、平均的な母音三角形や加速度を見る方がいいです。そのあたりはケースバイケースですね。でも、方言・年齢・性別は合わせるのは鉄則です。
たとえば、特別な母音のある方言もありますし、地域によって母音が微妙に違います。さらに、年齢も大切です。方言は15年ごとに微妙に変わっていきます。性別が違うと口の大きさが違うので、どこで母音を出しているのか、スピードの計算も変わってきます。
なるべく障害者に似たような人のデータを集めることが、よりよい修復に繋がります。完璧ではないですが、なるべく近づいた声にすることができますね。
無意味文テスト
――どの程度、音声を修復できているのでしょうか。
実際にどのくらい聞きやすい声になったのか、調査してみました。あるALS患者の方に、長期的な収録に協力してもらいました。初期、中期、さらに進行した状態で段階的に収録して、それぞれの段階で音声合成器をつくりました。はじめの段階で音声を収録していたので、本人としては必要ないのですが、研究のために協力してもらった形です。
ほぼ健常時の声で作った音声合成器と、障害が起った後の段階での音声合成器を比較しました。方法としては、人工的に無意味文をつくって聞き取りテストをしてもらいました。
――無意味文ってなんですか?
意味のある文章でやると、次に何を言うのか予測できてしまいます。ですが、それは音声合成器の評価にはならないですよね。ですので、次にくる単語が全く予測できない無意味文を用意して、何を言っているのか書き起こしてもらいました。
無意味文の書き起こしは非常に難しいです。健常時の声でつくると誤りが20%ほどでした。一方、障害のある声そのままでつくると50%。そこに修復プロセスを加えると、誤りが30%でしたので、聞きやすさを改善することができたと言えます。
やはり、健常時の声で出来るのが一番良いのですが、障害がおこってしまった段階であっても、ある程度は聞きやすさを改善できるということですね。
ボイスバンクプロジェクト
ポジティブな結果が得られたので、2011年ごろからスケールを広げてスコットランドを中心に、大規模に取り組むことにしました。数種類の運動ニューロンがかかわっている病気を対象にしたそのプロジェクトを「ボイスバンクプロジェクト」と呼んでいます。
――「ボイスバンク」良い名前ですね。
ここまで、説明してきたように、音声合成器を安く提供したり、障害のある声を修復するためには、患者さんの声だけではなくボランティアの方の声も必要です。
ボランティアの方に声の提供を募って、声のデータベースをつくり、そこから平均声をつくっています。最終的にはスコットランド全域の患者さんに音声合成器を提供することを目標にしています。
――ボランティアはどのように呼びかけているんですか。
パンフレットを大学病院などにおいています。「スタジオに来て喋るだけで、声に障害のある方の音声合成器の質が良くなります」と呼びかけています。それを読んで趣旨に同意してもらった方に、ホームページ上で収録するスタジオを選んでもらっています。
スタジオは、私のオフィスがある場所と、大学病院、スコットランドの国会議事堂にあります。
――国会議事堂にあるんですか。意外です。
国会議事堂にある記者室を無理やりスタジオに改装しています(笑)。隣にはBBCの方なんかもいますね。
実は、国会議事堂って声のサンプルを集めるのにとてもいい場所なんです。なぜなら、スコットランド全域から、小選挙区制で均等に選ばれた代表の方々がいるので、各地の方言を効果的に収集することができるんですね。
国会議員とそのサポーターの方を収集すれば、かなりの方言をカバーできることになります。国会議員というのは、地域の代表であると同時に、方言の代表そのものでもあるんです。
おかげさまで、国会議員の協力も得られましたので、沢山の地域の方言のサンプルが手に入りました。
実は、ボイスバンクのボランティアに参加することにはメリットがあります。万が一自分にも同じ病気が起こった時に、健常時の声を録音できているわけですから、それを基にした音声合成器を提供することができますよね。
――患者さんのためだけではく、ゆくゆくは自分のためになるかもしれないと。どのくらいの方がボランティアに参加されているのでしょうか。
2011年6月~2012年の5月までの1年間で400人ぐらい来ていただいています。今も少しずつ参加者が増えている状態です。
――使った方からの感想などはありましたか。
これまで30名ほどの患者さんの収録を終えました。スコットランド全域のALSの方の10%に相当します。その中で、10名の方の病気が進行しましたので、音声合成器をお届けしました。
そのうち8名の患者さんと、その家族からフィードバックをいただいています。5段階評価で平均して、「本人にどのくらい似ているのか」には3.5、「どのくらい明瞭に聞こえるのか」には4をいただきました。
「他の音声合成器と比べてどうか」という質問には、8名中7名の方がより良いと、評価してもらいました。
――高い評価ですね。
金銭、時間の面でも、患者さんの負担にならず、既存の音声合成器より質の高い
ものが提供できたのではと感じています。
自分の声が誰かの役に立つ
イギリスで、このような英語版のシステムを作ったので、似たような日本語のシステムにも取り組んでいます。ボランティアの方の声を日本全国4か所で収録しているんです。
今は500人ほどの収録が完了しました。もう少しデータがそろってきたら、これをベースに先ほど紹介した平均声と、声を修復するときのデータベースをつくる予定です。
――お話を聞いていると、ボイスバンクは痛くない献血のようだと思いました。
そうですね。実際にみなさん、困っている方を助けたいという気持ちはあると思うんですが、献血や臓器提供は勇気が必要ですよね。それに対して、ボイスバンクは気軽なので、やりたいと思ってくださる方が多くいらっしゃいます。
――日本ではどのような方が参加しているんですか。
身近に声の障害を抱えている人がいる、という方が多いです。患者の親戚の方、医療関係者の方が中心ですね。こういう領域はあまり知られていないので、知っている方は大変さをよく理解して、協力してくれます。
それと、意外に多いのは声優さんです。ボランティアで声を募るわけですから、声が商品の声優さんにはあまり受け入れてもらえないのではと、最初は思っていたのですが、みなさん協力していただけました。
みんなの声を混ぜて平均声をつくるので、必ずしも声優さんの声が単体で使われるわけではありません。声優さんたちもそのまま使われるわけじゃないので、安心して収録できます。
あとは、視覚障害者の方に本を音読してオーディオブックを作っている、音訳者の方々にもよく来ていただいています。
声に関わる活動をしている方には「自分たちが喋るだけで、困っている人を助けられる」というインパクトがあったようで、多くの方が協力してくださりました。
まだまだ、「ボイスバンク」はボランティアの方を募集しています。(特に、男性からの参加が少なく、重点募集をしております。) ぜひ、参加していただければと思いますね。
日本語ボイスバンクプロジェクトはこちら→http://www.nii.ac.jp/research/voicebank/
関連記事
■「ケアする、されるを超えて――ALS患者とミステリー作家が語るケアのその先」岡部宏生×葉真中顕

プロフィール

山岸順一
国立情報学研究所 コンテンツ科学研究系 准教授。音声情報処理の研究に従事。日本発の音声合成方式である統計的音声合成をコンペティション、EUの学術プロジェクトを等を通し、世界へ波及させることに尽力。また音声合成の福祉応用技術であるVoice Bankプロジェクトを英国・日本で展開し、音声の障碍者の生活の質を向上させるための基盤技術も研究・開発を行う。2014年文部科学大臣表彰 若手科学者賞受賞。